Teams are shipping AI-generated learning content faster than they can quality-check it — and a flawed module caught after launch costs far more than one caught at review. I designed a workshop that teaches practitioners to audit AI output against the learning objective before it reaches a learner, and piloted it with two practitioners using pre/post measurement.
At Ehoro Village, I was asked to build a workshop addressing a problem the team kept hitting: AI was letting us produce learning content faster than we could reliably quality-check it, and the cost of a flawed module isn't paid at the keyboard — it's paid downstream, after it reaches a learner. To scope it properly, I interviewed practitioners in the two worlds the workshop would serve — corporate L&D and higher education — to find where AI-generated content most often fails, then designed the session around closing that specific gap.
The Problem
Everyone's using AI. Few can tell when it's wrong.
AI made content drafting fast — but speed exposed a new gap. The output looks finished. It reads fluently, cites confidently, formats cleanly. The question nobody had a method for: is it actually good, before it reaches a learner?
I started the way I start any design problem — with research. I interviewed two senior practitioners across the two worlds I design for, one in corporate L&D and one in higher education, to understand how AI-generated content actually fails in their work. One theme ran through both conversations and became the thesis of the workshop: AI lets you execute faster, but that speed can push you to jump to solutions before the underlying problem has been properly diagnosed — and the same risk applies to the content AI hands you.
Needs Analysis
Diagnose before designing.
I synthesized the interviews into five findings and one performance gap. The most important move wasn't choosing what to teach — it was choosing what to cut.
01
The performance gap
Practitioners lack a structured method for evaluating AI-generated content at the point of review — before it reaches learners — so output that looks pedagogically sound can model the wrong behavior, flatten disciplinary voice, or pass off recall as rigor.
02
What I scoped out, and why
Enterprise governance, student-facing AI ethics, and large-scale localization all came up — and all got cut. They're organizational and policy problems, not skill gaps a 75-minute workshop can close. Naming the boundary kept the work focused on behavior I could actually change.
03
The checklist was derived, not invented
Every audit criterion is grounded in a specific failure mode the interviews surfaced. I turned those descriptions of how AI output goes wrong into checkable questions — so the checklist reflects real review problems, not a generic list of tips.
The Framework
Frame → Generate → Audit → Log.
I productized my own AI methodology — the one I authored across 24+ Ehoro build sessions — into four steps a practitioner can apply to any content task. Audit is the heart of it, and what separates this from generic "AI tips."
The Loop
FrameDefine objective, audience, constraints, and quality bar before prompting.
GenerateStructured prompts, then iterate — one variable at a time.
AuditEvaluate against seven criteria built from real failure modes.
LogDocument decisions so the workflow is reproducible.
Workshop slide — the four-step loop, with Audit weighted as the core skill
Key Design Decisions
Backward design, start to finish.
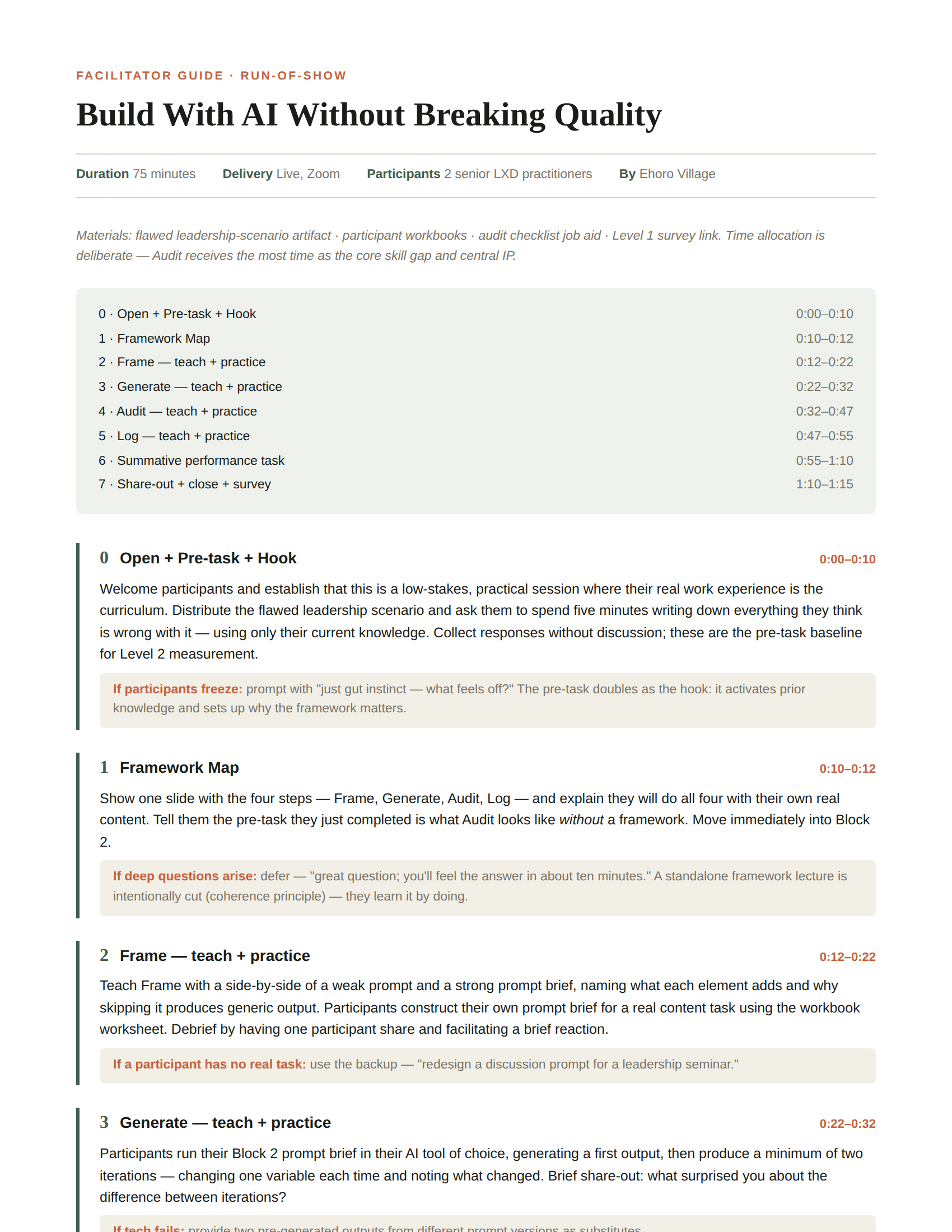
01 — Time follows the gap
Audit gets the most minutes.
Audit runs 15 minutes against 10 for every other step. It's the core skill gap from the needs analysis, so the time allocation follows the diagnosis, not convention.
02 — The hook is the pre-task
Let them fail before you teach.
I cut a standalone framework lecture. Participants meet a deliberately flawed AI module first and audit it cold — and that unaided baseline becomes the pre-measurement.
03 — Engineer the evidence in
One flaw per criterion.
The demo artifact carries exactly one flaw per checklist item, so the pre/post flaw-count captures the specific skill the workshop was built to produce — not a vague sense that it went well.
Artifacts
The full production package.
Every document below was built for this workshop. The process artifacts matter more than the polish.
The audit checklist job aid (left) and the needs analysis brief (right)
Facilitator guide run-of-show (left) and a participant workbook page (right)
I ran the workshop as a pilot with two senior practitioners — one in corporate L&D, one in higher education — using a pre/post measurement built into the session and a short follow-up two weeks later. With a cohort of two, the findings are directional, not statistical, and I report them that way. What I was testing was simple: does the checklist change what a reviewer catches?
Level 1 · Reaction
Relevant to real work.
Both rated the session highly relevant to their day-to-day, and both reported higher confidence auditing AI output afterward than before — each also naming the conditions under which they'd still want a second reviewer.
Level 2 · Learning
Instinct, then method.
Auditing the same flawed module first unaided, then with the checklist, both participants caught noticeably more of the planted flaws with the tool in hand — the gain concentrated in the failure types they'd each missed on instinct.
Level 3 · Behavior
It left the room.
At the two-week follow-up, both reported having applied the framework to real work — building a review step into their own AI-assisted content process.
What I'd measure next
Toward business impact.
A two-person pilot can't show downstream results at scale. The next run is designed to track whether the review step actually reduces flaws reaching learners — the Level 4 question this pilot was too small to answer.
The most useful finding came from the contrast between the two: each reviewer's instinct was sharp but domain-specific — the gaps they missed unaided were different. That divergence is the whole argument for a shared checklist, and a two-week pilot surfaced it more clearly than I'd expected.
Reflection
What the pilot changed.
A pilot is only worth running if you let it change the work. Watching the two sessions surfaced a real irony in my own design: the audit criteria were sound, but every worked example I'd used to teach them drew on soft-skills content — so the checklist meant to catch "this could be for anyone" was itself generic in how it taught. I added a parallel technical-content column to the facilitator guide, so each flaw now shows up in both a leadership and a certification context. One workshop, both audiences.
A second, smaller fix: the Log step felt rushed at the end, so I made its asynchronous-completion option prominent rather than buried in a contingency note. The temptation after a pilot is to redesign everything. The discipline is changing only what the evidence supports — and being able to say exactly why.
How This Was Made
AI helped draft it. Judgment shaped it.
In keeping with the framework this workshop teaches, I'll be transparent about my own process. I used AI as a drafting partner for several of the production artifacts — the needs analysis brief, the facilitator guide, and the participant workbook — generating first passes I then audited, rewrote, and shaped against the interview data and my own design decisions.
The thinking is mine: the performance gap, what to scope out, the seven audit criteria, the time allocation, the assessment design, and every revision made from the pilot. AI accelerated the writing; it didn't make the calls. That's the entire point of Frame → Generate → Audit → Log — and applying it to my own work is the most honest demonstration of it I can offer.